


J. Imaging 2024, 10(6), 133; https://doi.org/10.3390/jimaging10060133 (registering DOI) - 29 May 2024
Abstract
Abstract: Accurate and robust 3D human modeling from a single image presents significant challenges. Existing methods have shown potential, but they often fail to generate reconstructions that match the level of detail in the input image. These methods particularly struggle with loose
[...] Read more.
Abstract: Accurate and robust 3D human modeling from a single image presents significant challenges. Existing methods have shown potential, but they often fail to generate reconstructions that match the level of detail in the input image. These methods particularly struggle with loose clothing. They typically employ parameterized human models to constrain the reconstruction process, ensuring the results do not deviate too far from the model and produce anomalies. However, this also limits the recovery of loose clothing. To address this issue, we propose an end-to-end method called IHRPN for reconstructing clothed humans from a single 2D human image. This method includes a feature extraction module for semantic extraction of image features. We propose an image semantic feature extraction aimed at achieving pixel model space consistency and enhancing the robustness of loose clothing. We extract features from the input image to infer and recover the SMPL-X mesh, and then combine it with a normal map to guide the implicit function to reconstruct the complete clothed human. Unlike traditional methods, we use local features for implicit surface regression. Our experimental results show that our IHRPN method performs excellently on the CAPE and AGORA datasets, achieving good performance, and the reconstruction of loose clothing is noticeably more accurate and robust.
Full article
(This article belongs to the Special Issue Self-Supervised Learning for Image Processing and Analysis)






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
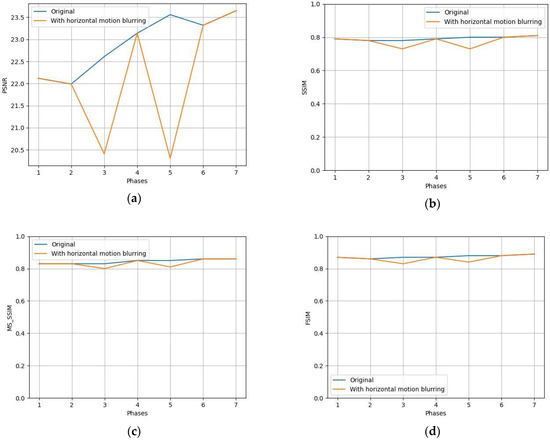{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}