

Computers 2024, 13(6), 130; https://doi.org/10.3390/computers13060130 (registering DOI) - 23 May 2024
Abstract
The diversity and scarcity of resources across devices in heterogeneous computing environments can impact their ability to meet users’ quality-of-service (QoS) requirements, especially in open real-time environments where computational loads are unpredictable. Despite this uncertainty, timely responses to events remain essential to ensure
[...] Read more.
The diversity and scarcity of resources across devices in heterogeneous computing environments can impact their ability to meet users’ quality-of-service (QoS) requirements, especially in open real-time environments where computational loads are unpredictable. Despite this uncertainty, timely responses to events remain essential to ensure desired performance levels. To address this challenge, this paper introduces collaborative service execution, enabling resource-constrained IoT devices to collaboratively execute services with more powerful neighbors at the edge, thus meeting non-functional requirements that might be unattainable through individual execution. Nodes dynamically form clusters, allocating resources to each service and establishing initial configurations that maximize QoS satisfaction while minimizing global QoS impact. However, the complexity of open real-time environments may hinder the computation of optimal local and global resource allocations within reasonable timeframes. Thus, we reformulate the QoS optimization problem as a heuristic-based anytime optimization problem, capable of interrupting and quickly adapting to environmental changes. Extensive simulations demonstrate that our anytime algorithms rapidly yield satisfactory initial service solutions and effectively optimize the solution quality over iterations, with negligible overhead compared to the benefits gained.
Full article
(This article belongs to the Special Issue Intelligent Edge: When AI Meets Edge Computing)


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
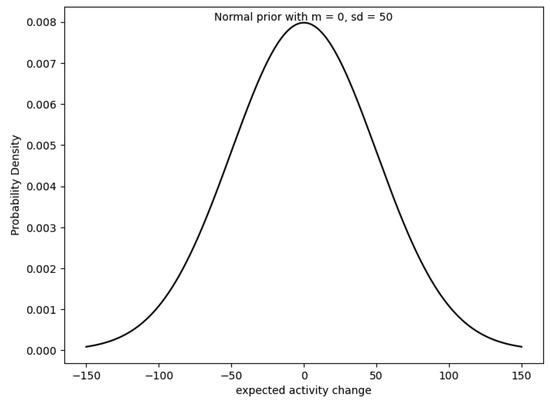{kind=link}
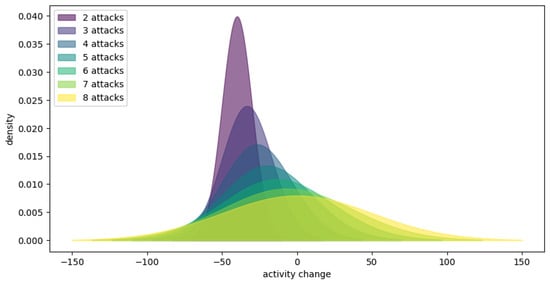{kind=link}
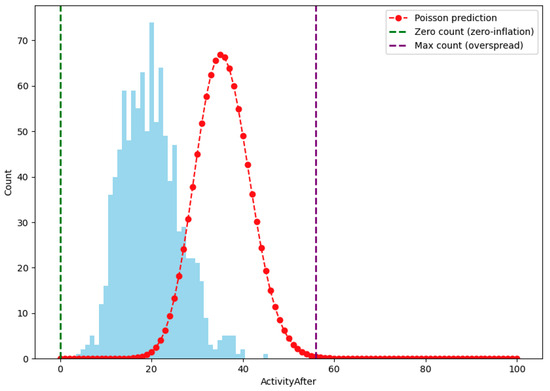{kind=link}
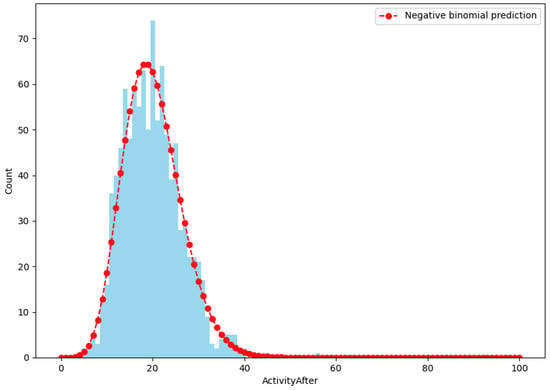{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
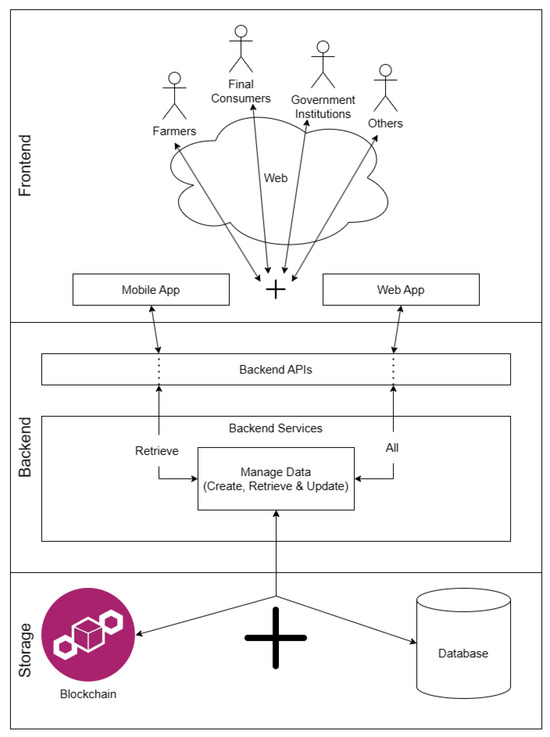{kind=link}
{kind=link}
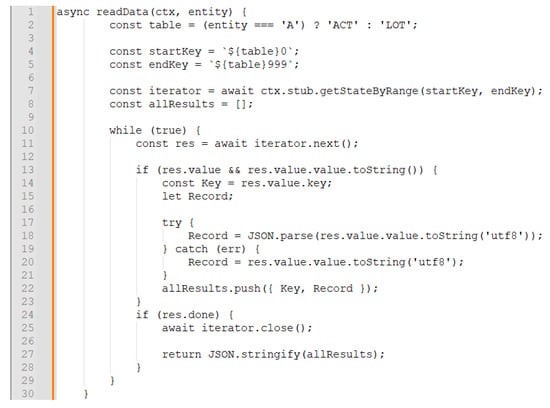{kind=link}
{kind=link}
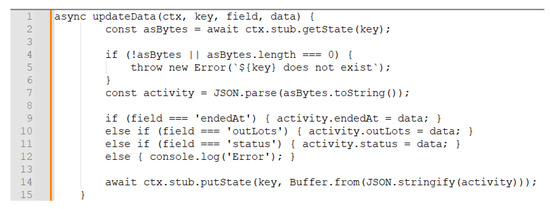{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}